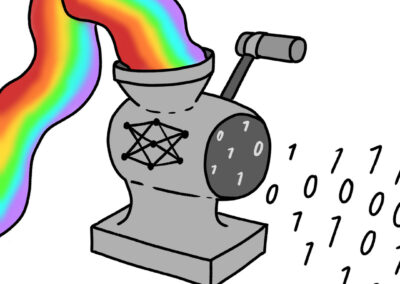
Not semantic, but statistical.
The most important thing to understand about AI chatbots is also counterintuitive: they don’t know what language means. They don’t read, reason, or understand. They operate statistically, predicting the most probable next word based on patterns learned from enormous amounts of text. When you ask a large language model (LLM) a question, it doesn’t look up an answer or reason through the problem. It finds the statistically likely continuation of your input, based on what has appeared near similar text, millions of times, in its training data. The output can sound remarkably coherent and confident. But coherence and correctness are two different things.

To make this understandable, the session drew on word2vec: a technique where words are mapped into a mathematical space based on how often they appear near each other. The workshop turned this into a playful food exercise, food2vec: participants had to guess where foods are positioned in a two-dimensional space. If an apple is on the far side of fruits, where would a piece of bread be positioned?

A talk on “LLMs, Power and Knowledge”
As part of GIZ’s AI Month, organised by the GIZ digital gateway, over 480 GIZ colleagues joined an online talk by Calle Reuter (Physics, Political Science, Feminist Science & Technology Studies, Freie Universität Berlin) and Paula Kilp. The session placed AI tools within a broader framework of power and knowledge. It asked not just how these tools work, but who benefits from them and whose knowledge they reflect.
Who builds and “controls” AI?
The talk framed power as the “structural privilege and oppression” and knowledge as “situated”, meaning it is produced by specific people in specific cultural, historical, and geographic circumstances. These definitions set AI technologies into a political context. The question that naturally followed was: who can actually build and run these models? Large data centres, where big AI models are running, are owned by a small number of actors. This monopolisation creates dependencies for everyone else. Another factor that is often overlooked is the high energy and water demand of these centres. The usage of training data incorporates questions of power regarding IP and workforce: for example, when GEMA won a lawsuit against OpenAI for using song lyrics or the huge amount of human labour that is needed for preparing training data.
When statistics encode bias
Both the workshop and talk mentioned various important examples for when an output of an LLM is biased. They reflect the text they were trained on and that text reflects the world in the way it is written about, not as it is. For example, gender bias in translation processes: a sentence describing someone as a nurse was translated with feminine pronouns; a sentence describing a scientist, with masculine ones. For an organisation working in international development, where inclusive and context-sensitive information is central to the work, this understanding is crucial. To put it clearly: “LLMs have a tendency to bias towards the median. Minorities will not be well represented in this output, which can be a source of harm.” (Kilp). Groups that are underrepresented or misrepresented in the training data will be underrepresented or distorted in the model’s outputs.
What this means for how we use AI
Understanding the nature of LLMs can lead to better practice. As a user you can follow these interpretations:
- Fluency is not accuracy: A confident, well-written output is not a reliable one. The model does not know whether what it generated is true. It only knows what was probable.
- Bias is structural, not accidental: AI reflects biases in its training data. Outputs about underrepresented groups and topics deserve extra caution.
- Knowing when to use or refuse it: Knowing that AI works statistically leads to better prompts, more verification, and skepticism without dismissing AI’s general usefulness.

A representation of how LLMs get to their output. (by Paula Kilp and Calle Reuter)
Using AI critically
The goal is not to make people avoid these tools. AI chatbots can be useful, for example for drafting, brainstorming or summarizing. But usefulness without questioning can lead to blind over-reliance. And this can lead to mistakes that nobody catches because the output looks plausible. This shift in mindset is part of what it means to use AI critically.
Workshop (18 March, GIZ Eschborn) presented by Paula Kilp. Online talk (6 May 2026, AI Month by GIZ digital gateway) presented by Calle Reuter and Paula Kilp. Both as part of the “if-then-but-why?”-series. Hosted by the GIZ Data Lab. More sessions to follow.